

Decoders for Automatic Speech Recognition
Automatic Speech Recognition (ASR) systems convert speech from a recorded audio signal to text. An ASR system aims to infer the original words given an observable signal, most commonly following a probabilistic approach [1].
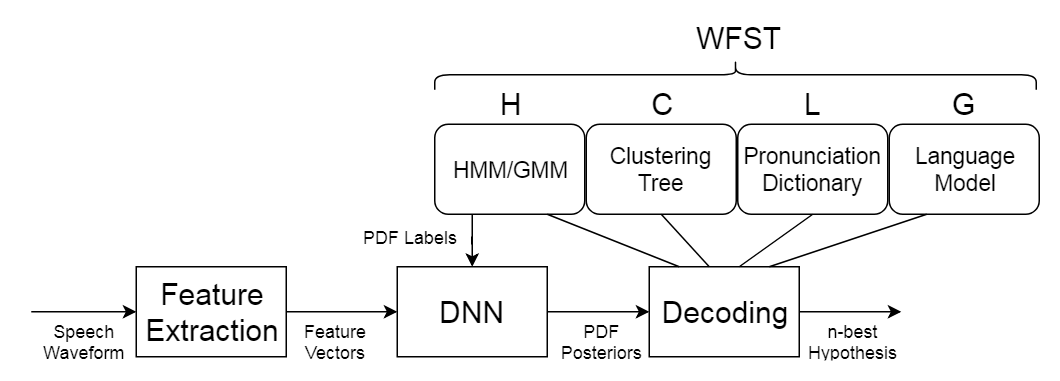
Figure 1: Diagram of an ASR system.
The input audio is split into overlapping frames of 25ms shifted by 10ms, so that within this tiny time window, the speech signal is considered to be stationary, allowing for the analysis featured here. Before decoding, these are fed to a feature extractor, which reduces signal dimensionality and extracts the most relevant information, that is, the linguistic message.
Decoding is the process of calculating which sequence of words is most likely to match the acoustic signal represented by the feature vectors [1] of a given utterance (a continuous piece of speech beginning and ending with a clear pause). Decoding is executed based on three sources of information:
- Acoustic model: An ensemble of Hidden Markov Models representing words or phonemes;
- Language model: A list of word sequence probabilities;
- Lexicon: A dictionary of words and their respective phonemes.
During decoding, we essentially use these to try to predict the word sequence $\hat{W}$ that best matches the acoustic observation $\boldsymbol{X}=X_1 X_2\ldots X_n$, obtained using Bayes rule:
\[\begin{equation*} \begin{split} \boldsymbol{\hat{W}} &= arg\max_{\boldsymbol{W}}P(\boldsymbol{W}\mid \boldsymbol{X})\\ &= arg\max_{\boldsymbol{W}}\frac{P(\boldsymbol{X}\mid \boldsymbol{W})P(\boldsymbol{W})}{P(\boldsymbol{X})}\\ &\propto arg\max_{\boldsymbol{W}} (\underbrace{P(\boldsymbol{X} \mid \boldsymbol{W})}_{\substack{\text{Acoustic} \\ \text{model}}} \underbrace{P(\boldsymbol{W})}_{\substack{\text{Language} \\ \text{model}}}) \end{split} \end{equation*}\]The acoustic analysis is performed by a Deep Neural Network, which is trained to output the posterior probability $P(\boldsymbol{X} \mid \boldsymbol{W})$ of obtaining this observation given a candidate word sequence. The prior probability $P(\boldsymbol{W})$ of a word sequence is obtained from a language model, containing the allowed and most frequent occurrences for a given language. Therefore, prior probability and posterior likelihood are combined in order to output the best prediction with the available information.
One solution for the search of the best word sequence involves the use of Weighted Finite State Transducers (WFSTs). I wrote about it in this post, if you feel up for the challenge.


Comments